Streaming Input Dataset¶
We already covered the basics of an iterable dataset (Python basics) and pytorch’s DataLoader (pytorch introduction). In this notebook, we introduce a few datasets that will be used during the hands-on sessions, and practic looping over the dataset using DataLoader!
import torch
import numpy as np
SEED=123
np.random.seed(SEED)
torch.manual_seed(SEED)
<torch._C.Generator at 0x7fe5c4b35110>
MNIST dataset¶
MNIST is widely used for an introductory machine learning (ML) courses/lectures. Most, if not all, ML libraries provide an easy way (API) to access MNIST and many publicly available dataset. This is true in pytorch as well. MNIST dataset in Dataset instance is available from torchvision.
Creating MNIST Dataset¶
A torchvision is a supporting module that has many image-related APIs including an interface (and management) of MNIST dataset. Let’s see how we can construct:
import os
from torchvision import datasets, transforms
# Data file download directory
LOCAL_DATA_DIR = './mnist-data'
os.makedirs(LOCAL_DATA_DIR,exist_ok=True)
# Use prepared data handler from pytorch (torchvision)
dataset = datasets.MNIST(LOCAL_DATA_DIR, train=True, download=True,
transform=transforms.Compose([transforms.ToTensor()]))
/usr/local/lib/python3.8/dist-packages/torchvision/datasets/mnist.py:498: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
Here, MNIST is also a type Dataset (how? through class inheritance). All torch Dataset instance have tow useful and common functions: the length representations and data element access via index.
print( len(dataset) )
print( type(dataset[0]) )
60000
<class 'tuple'>
That being said, how each data element is presented depends on a particular Dataset implementation. In case of MNIST, it is a tuple of length 2: data and label.
ENTRY=0
data, label = dataset[ENTRY]
print('Type of data :', type(data), 'shape', data.shape)
print('Type of label :', type(label), 'value', label)
Type of data : <class 'torch.Tensor'> shape torch.Size([1, 28, 28])
Type of label : <class 'int'> value 5
MNIST is an image of a hand-written digit in 28x28 pixels, gray scale. Note that the data shape is [1,28,28]. This follows the convention in Pytorch for image data represented as \((Cannel,Height,Width)\), or in short \((C,H,W)\). Let’s visualize using matplotlib.pyplot.imshow. This function can take \((H,W)\) of a gray scale image.
import matplotlib.pyplot as plt
%matplotlib inline
# Draw data
data = data.reshape(data.shape[1:])
plt.imshow(data,cmap='gray')
plt.show()
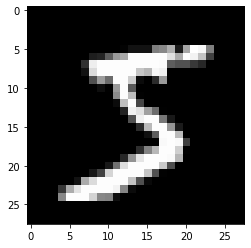
Let us define a function that can list images and labels in the dataset.
def plot_dataset(dataset,num_image_per_class=10):
import numpy as np
num_class = 0
classes = []
if hasattr(dataset,'classes'):
classes=dataset.classes
num_class=len(classes)
else: #brute force
for data,label in dataset:
if label in classes: continue
classes.append(label)
num_class=len(classes)
shape = dataset[0][0].shape
big_image = np.zeros(shape=[3,shape[1]*num_class,shape[2]*num_image_per_class],dtype=np.float32)
finish_count_per_class=[0]*num_class
for data,label in dataset:
if finish_count_per_class[label] >= num_image_per_class: continue
img_ctr = finish_count_per_class[label]
big_image[:,shape[1]*label:shape[1]*(label+1),shape[2]*img_ctr:shape[2]*(img_ctr+1)]=data
finish_count_per_class[label] += 1
if np.sum(finish_count_per_class) == num_class*num_image_per_class: break
import matplotlib.pyplot as plt
fig,ax=plt.subplots(figsize=(8,8),facecolor='w')
ax.tick_params(axis='both',which='both',bottom=False,top=False,left=False,right=False,labelleft=False,labelbottom=False)
plt.imshow(np.transpose(big_image,(1,2,0)))
for c in range(len(classes)):
plt.text(big_image.shape[1]+shape[1]*0.5,shape[2]*(c+0.6),str(classes[c]),fontsize=16)
plt.show()
Visualize!
plot_dataset(dataset)

Creating DataLoader¶
Since the MNIST dataset is an iteratable one, we can create pytorch DataLoader!
import torch
loader = torch.utils.data.DataLoader(dataset,
batch_size=20,
shuffle=True,
num_workers=1,
pin_memory=True)
Review: the first argument is you dataset, and it can be anything but requires two attributes: __len__ and __getitem__. In case you wonder, these attributes allow you to call len(dataset) and access dataset elements by dataset[X] where X is an index integer.
Details (ignore if wished): other constructor arguments¶
The other constructor arguments used above are:
batch_size… the same of the subset data to be provided at onceshuffle… whether or not to randomize the choice of subset dataset (False will provide datasetnum_workers… number of parallel data-reader processes to be run (for making data read faster usingmultiprocessingmodule)pin_memory… speed up data transfer to GPU by avoiding a necessity to copy data from pageable memory to page-locked (pinned) memory. Read here for more details. If you are not sure about the details, set toTruewhen using GPU.
Data streaming with DataLoader¶
So let’s play with it! First of all, it has the concept of “length”.
print('length of DataLoader:',len(loader))
print('By the way, batch size * length =', 20 * len(loader))
length of DataLoader: 3000
By the way, batch size * length = 60000
We know the data total statistics is 60,000 which coincides with the length of DataLoader instance and the batch size where the latter is the unit of batch data. Yep, as you guessed, DataLoader is iterable:
# Create an iterator for playin in this notebook
from itertools import cycle
iter = cycle(loader)
for i in range(10):
batch = next(iter)
print('Iteration',i)
print(batch[1]) # accessing the labels
THCudaCheck FAIL file=/pytorch/aten/src/THC/THCCachingHostAllocator.cpp line=278 error=2 : out of memory
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_46560/3328099877.py in <module>
4
5 for i in range(10):
----> 6 batch = next(iter)
7 print('Iteration',i)
8 print(batch[1]) # accessing the labels
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in __next__(self)
519 if self._sampler_iter is None:
520 self._reset()
--> 521 data = self._next_data()
522 self._num_yielded += 1
523 if self._dataset_kind == _DatasetKind.Iterable and \
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in _next_data(self)
1201 else:
1202 del self._task_info[idx]
-> 1203 return self._process_data(data)
1204
1205 def _try_put_index(self):
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in _process_data(self, data)
1227 self._try_put_index()
1228 if isinstance(data, ExceptionWrapper):
-> 1229 data.reraise()
1230 return data
1231
/usr/local/lib/python3.8/dist-packages/torch/_utils.py in reraise(self)
423 # have message field
424 raise self.exc_type(message=msg)
--> 425 raise self.exc_type(msg)
426
427
RuntimeError: Caught RuntimeError in pin memory thread for device 0.
Original Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 34, in _pin_memory_loop
data = pin_memory(data)
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 58, in pin_memory
return [pin_memory(sample) for sample in data]
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 58, in <listcomp>
return [pin_memory(sample) for sample in data]
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 50, in pin_memory
return data.pin_memory()
RuntimeError: cuda runtime error (2) : out of memory at /pytorch/aten/src/THC/THCCachingHostAllocator.cpp:278
… and this is how data looks like:
print('Shape of an image batch data',batch[0].shape)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_46560/911477057.py in <module>
----> 1 print('Shape of an image batch data',batch[0].shape)
NameError: name 'batch' is not defined
… which is quite naturally 20 of 28x28 image
CIFAR10¶
CIFAR10 is yet another public dataset of 32x32 pixels RGB photographs. It contains 10 classes like MNIST but it is much more complicated than a gray scale, hand-written digits.
from torchvision import datasets, transforms
# Data file download directory
LOCAL_DATA_DIR = './cifar10-data'
# Create the dataset
dataset = datasets.CIFAR10(LOCAL_DATA_DIR, train=True, download=True,
transform=transforms.Compose([transforms.ToTensor()]))
plot_dataset(dataset)
Files already downloaded and verified

Nothing new in terms of how-to, but let’s also create a DataLoader with CIFAR10.
loader = torch.utils.data.DataLoader(dataset,batch_size=8,shuffle=True,num_workers=1,pin_memory=True)
batch = next(cycle(loader))
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_46560/1749979711.py in <module>
1 loader = torch.utils.data.DataLoader(dataset,batch_size=8,shuffle=True,num_workers=1,pin_memory=True)
2
----> 3 batch = next(cycle(loader))
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in __next__(self)
519 if self._sampler_iter is None:
520 self._reset()
--> 521 data = self._next_data()
522 self._num_yielded += 1
523 if self._dataset_kind == _DatasetKind.Iterable and \
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in _next_data(self)
1201 else:
1202 del self._task_info[idx]
-> 1203 return self._process_data(data)
1204
1205 def _try_put_index(self):
/usr/local/lib/python3.8/dist-packages/torch/utils/data/dataloader.py in _process_data(self, data)
1227 self._try_put_index()
1228 if isinstance(data, ExceptionWrapper):
-> 1229 data.reraise()
1230 return data
1231
/usr/local/lib/python3.8/dist-packages/torch/_utils.py in reraise(self)
423 # have message field
424 raise self.exc_type(message=msg)
--> 425 raise self.exc_type(msg)
426
427
RuntimeError: Caught RuntimeError in pin memory thread for device 0.
Original Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 34, in _pin_memory_loop
data = pin_memory(data)
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 58, in pin_memory
return [pin_memory(sample) for sample in data]
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 58, in <listcomp>
return [pin_memory(sample) for sample in data]
File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/pin_memory.py", line 50, in pin_memory
return data.pin_memory()
RuntimeError: cuda runtime error (2) : out of memory at /pytorch/aten/src/THC/THCCachingHostAllocator.cpp:278
Let’s take a look at the batch data. Recall the shape of this image \((C,H,W)\) where matplotlib.pyplot.imshow takes the format \((H,W,C)\) just like how an ordinary photograph is presented. We use torch.permute function to swap the axis.
photos,labels=batch
for idx in range(len(photos)):
photo = photos[idx].permute(1,2,0)
label = labels[idx]
print(dataset.classes[label])
plt.imshow(photo)
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_46560/1216954958.py in <module>
----> 1 photos,labels=batch
2 for idx in range(len(photos)):
3 photo = photos[idx].permute(1,2,0)
4 label = labels[idx]
5 print(dataset.classes[label])
NameError: name 'batch' is not defined